Introduction
As a solution engineer, it is my mandate to advocate large IT organizations on how to best leverage the tools available in the market to empower their users to be autonomous. In the world of big data, this has many aspects from defining business processes to ensuring security and governance. The key aspect however is the ability to “shift to the left”, meaning that the end user is in control of the infrastructure necessary for his job.
Ultimately this is the unicorn every organization wants: a highly guarded infrastructure that feels like a plain of freedom to the end user.
Some organizations choose to use one vendor (e.g. cloud vendor) to implement this unicorn vision, but soon realize (or will soon) that the limiting yourself to one vendor not only restrict the plain field of end users it paradoxically make the implementation of consistent governance and security harder (because of vendor limitations and a tendency towards restricting cross platform compatibility)
The solution is what I advice my customer every day: building the backbone of an organization on open inter compatible standards that allow growth while maintaining consistency. In today’s world, it’s the hybrid cloud approach.
When I joined Hortonworks (now Cloudera) a few months ago I was impressed by the work done by a few Solution Engineers (Dan Chaffelson and Vadim Vaks). They had built an automation tool that would allow any Solution Engineer in the organization to spin their own demo cluster and load whatever demo they want called Whoville. I led a Pre-Sales organization before: this is the dream. Having consistency over demos for each member of the organization while empowering the herd of cats that Solution Engineers are is no easy feat. Not only that, we were eating our own dog food, leveraging our tools to instantiate what we had been preaching!
I’m still in awe of the intelligence and competency of the team I just joined. But, being as lazy as I am, I decided to try and build an even easier button for Whoville which would:
1. Empower the rest of our organization even more
2. Show true thought leadership to our customers
So with the help of my good friend Josiah Goodson and the support of the Solution Engineering team (allowing us to work on this during a hackathon for instabce) we built Cloudbreak Cuisine.
Introducing Cloudbreak Cuisine
Cuisine is fully featured application, running in containers, that allows, in its alpha version, Solution Engineers to:
1. Get access to Whoville library, deploy and delete demo clusters
2. Monitor clusters deployment via Cloudbreak API
3. Create your own combination of Cloudbreak Blueprints & Recipes (a.k.a. bundles) for your own demo
4. Push those bundles to Cloudbreak
Below is a high level architecture of Cuisine:
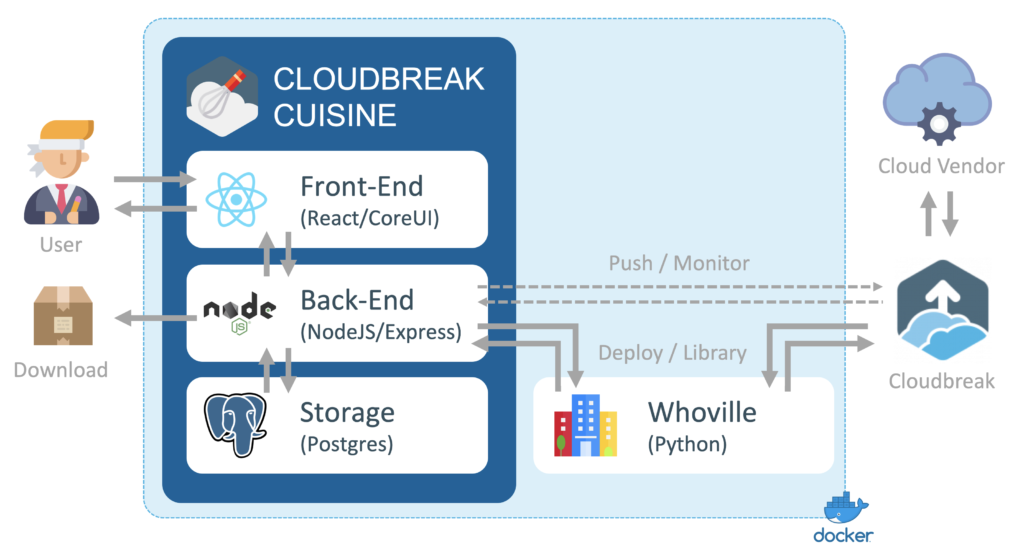
The deployment of the tool is automated, but requires access to Whoville (restricted within our own organization). All details can be found here: https://github.com/josiahg/cloudbreak-cuisine
The couple of videos below showcase what Cuisine can do, in its alpha version.
Glossary: Cuisine Bundles are a combination of Cloudbreak Blueprints & Recipes.
Features
Push a bundle from Whoville
Delete a Bundle via Cloudbreak
Add Custom Recipe
Create Custom Bundle
Download/Push Bundle
Additional tips/tricks
Parting thoughts
First and foremost: thank you. Thank you Dan and Vadim for Whoville, thank you Josiah for your continuous help and thank you Hortonworks/Cloudera to allow us to be demonstrating such thought leadership.
Secondly, if you’re a Cloudera Solution Engineer, test it and let me know what you think!
Finally, for every other reader out there: this is what an open platform can do to your organization. Truly allow you to leverage any piece of data or any infrastructure available to you; from EDGE to AI :)