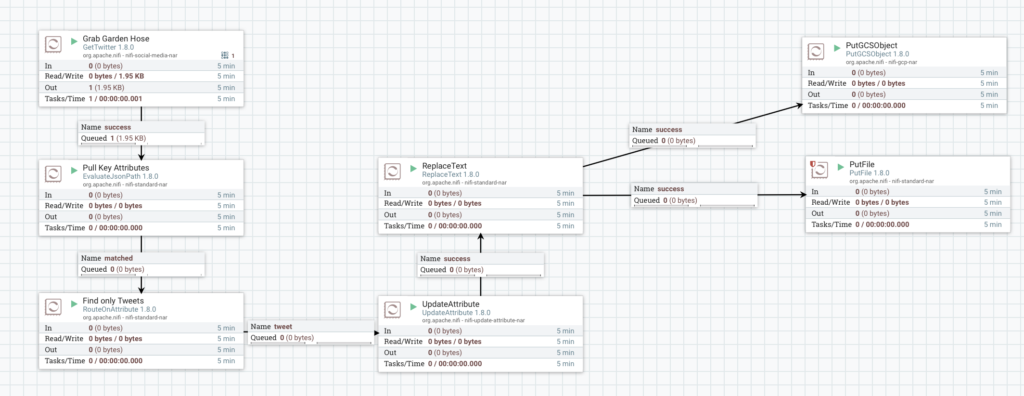
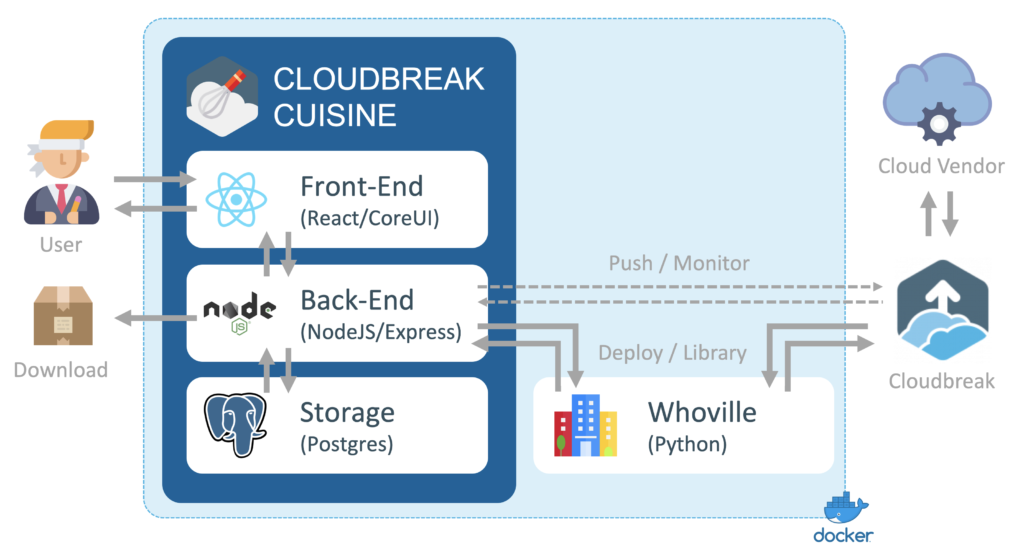
I am always humbled and grateful by the persons I get to work with. I often find myself amazed (in the real sense of the term) and inspired by the intellectual journey of the people I encounter in the world of data. The data industry is at the forefront of human advancement: self driving cars, social networks, rocket launches, cyber attack prevention, medicine advancements, genomics… all fueled by data.
As technology advances, society advances and with it our code of ethics or what is considered morally good. A great example of that is applying modern standards of ethics to a generation or two before us. I’m sure we all had uncomfortable conversations with grand-parents.
Recently, one of the most mind boggling problem of ethics surrounds machine learning and artificial intelligence. Whether it is responding to sci-fi skynet-like ideas of artificial consciousness, or more down to earth considerations such as yet another iteration of a trolley problem substituting the subject with a self driving car, you will see write-ups popping up everywhere (often by people that don’t know much about the field). Of course, this work is important, and if you want to read a good book about this, here is the reference: Ethics and Data Science, by DJ Patil, Hilary Mason, Mike Loukides.
You do not need data science to think about ethics
Here is the core of my argument: you do not need data science to think about ethics. Ethics should be part of every piece of software brought to the public, especially when dealing with data.
Growing up, I was inspirited by Google’s modo: “Don’t be evil”, which later changed to “Do the right thing” (see wikipedia). Unfortunately, a few years later, I feel a different code of conduct coming from certain software companies, especially those who are at the center of our lives like social media.
Facebook is an example that comes very easily to mind, with recent scandals such as the Cambridge Analytica scandal. For those who need more that a moral reason of why that type of scandal is bad, look at the recent news and the exec that are leaving Facebook. Not considering ethics is just bad for business. Read the Power Paradox to get a bit more context.
Not considering ethics is just bad for business.
Now, I’m not an idealist that thinks that Facebook will give such a great service to the world without trying to monetize it. So much so that I was brought up with the idea of: if you don’t want something to be known, you should not put it on the internet. Here is the problem though: as our society evolves, this motto will be impossible to follow. Your personal data will be available on the next generation of quantum ai driven global network, or whichever buzz wordy combination makes you think of the future of technology.
This is why it is important to consider ethics now.
For software companies, it means enabling your customer to evaluate your ethics. I think that it would be done following these 3 pillars:
- Transparency: If a social network comes to me and says: look, we are going to use your data to target adds at you, but we will never leak it to organizations promoting political campaigns and you get to see exactly which data is given to whom, I’m in! This is true for social medias, but for cloud, Software as a Service as well. If I am a small business and I subscribe to a payment processing engine, I want to know how you are using my sales data.
- Openness: Software companies should not only tell us who uses our data, you should tell us what type of algorithms you use to create your software (not necessarily opening the code, but at least an idea of the architecture)
- Accountability: Finally, if a company makes a mistake, own it and communicate it to the public. This seems obvious to me but apparently not common practice
For users, we need to vote with our decisions. I want companies to consider ethics to be an equally important consideration as customer satisfaction for instance, though I believe that in the long run, both are closely related. This is why I stopped using certain social networks, and I spent my days fighting against bad practices in the world of large enterprises software.
I realize defining and observing a code of ethics is difficult and that it is a moving target. Nevertheless, I feel that the software industry engine, and its oil that is data does not have the appropriate ethics institutions in place. I’d like for this to change.