Introduction & Context
There is a reason why I spent my life studying and working in computer science: understanding a computer’s psychology is usually fairly straight forward. Indeed, when presented with a specific input, computer programs tend to respond in a very predictable way, as opposed to our fellow human beings. Of course, this observation goes out of the window as our algorithms become increasingly more complex and capable of learning.
Regardless, as much as I love computer science, I always had a keen interest in human sciences. Personality psychology is a fascinating subject that has seen its ups and downs as any science topic. At the center of personality psychology reside the big five personality traits:
- Openness to Experience
- Conscientiousness
- Extraversion
- Agreeableness
- Neuroticism (or Emotional Stability)
This taxonomy was determined by applying statistical models to personality surveys, essentially clustering results of surveys of people describing fellow human beings. As such, these traits are meant to categorize common aspect of personality across human beings without moral connotation. The validity of the model and its predictability for real life outcomes is of course controversial, and I wouldn’t make it justice here (I most likely already irritated any personality psychologist that read these first few lines).
Recently, multiple machine learning algorithms have been designed to determine these 5 personality traits from texts have surfaced, including IBM Watson personality insights. For this article I chose to use the personality recognizer written by Francois Mairesse, and automate personality detection of New York Times articles using HDF 3.1 and HDP 3.0.
Solution Overview
The solution put in place uses 3 main elements:
- A NiFi flow to orchestrate data ingestion from API, personality detection and storage to Hive
- Hive to store the results of the personality detection
- Zeppelin for visualization of the results
The figure below gives an overview of the solution flow:
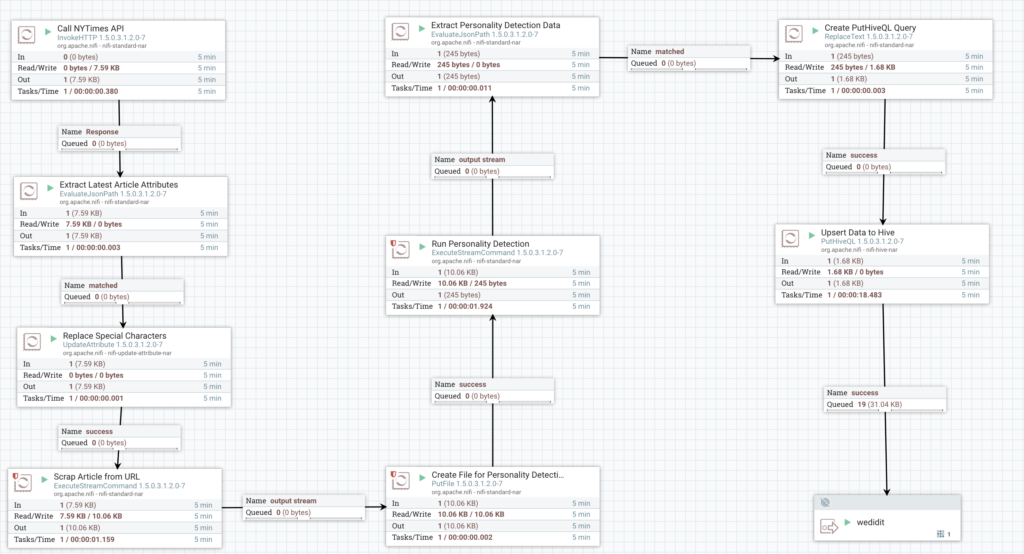
More precisely, the solution can be dissected in 5 main steps, that I’m describing in details below:
- Step 1: Retrieving data from New York Times API
- Step 2: Scrape HTML article data
- Step 3: Run machine learning models for personality detection
- Step 4: Store results to Hive
- Step 5: Create simple Zeppelin notebook
Step 1: Retrieving data from New York Times API
Obtaining an API Key
This step is very straight forward. Go to https://developer.nytimes.com/signup and sign-up for a key:
Note: The New-York Times API is for non-commercial use only. I could have of course used any news API, but I’m not creative.
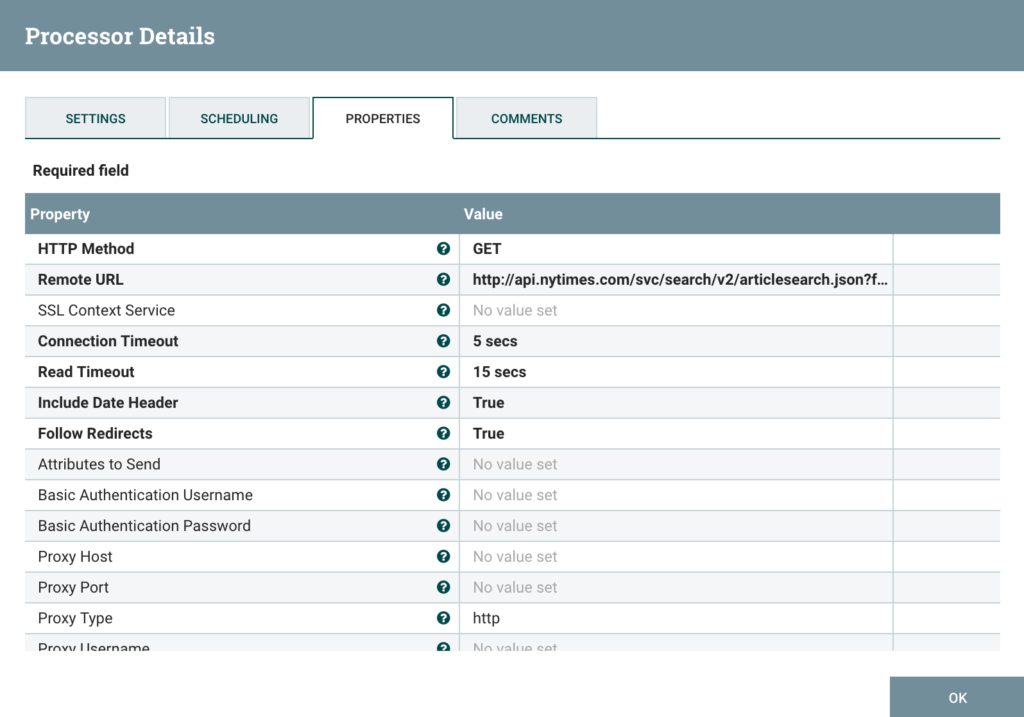
Configuring InvokeHTTP
The InvokeHTTP is used here with all default parameters, except for the URL. Here are some key configuration items and a screenshot of the Processor configuration:
- HTTP Method: GET
- Remote URL: http://api.nytimes.com/svc/search/v2/articlesearch.json?fq=source:(“The New York Times”)&page=0&sort=newest&fl=web_url,snippet,headline,pub_date,document_type,news_desk,byline&api-key=[YOUR_KEY] (This URL selects article from the New York Times as a source, and only selects some of the fields I am interested in: web_url,snippet,headline,pub_date,document_type,news_desk,byline).
- Content-Type: ${mime.type}
- Run Schedule: 5 mins (could be set to a little more, I’m not sure the frequency at which new articles are published)
Extracting results from Invoke HTTP response
The API call parameter page=0 returns results 0-9; for this exercise, I’m only interested in the latest article, so I setup an evaluateJSONpath processor take care of that, as you can see below:
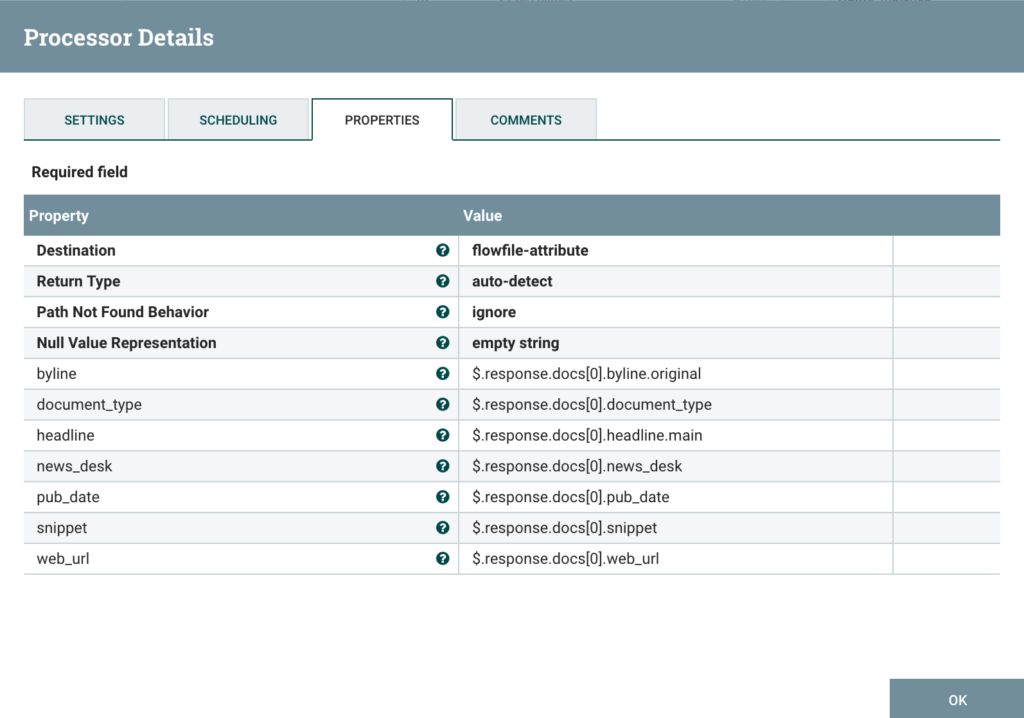
A few important points here:
- The destination is set to flowfile-attribute because we are going to re-use these attributes later in the flow
- I’m expecting the API to change after some time this article is published. Just to make sure that the JSON paths are good for your version of the API, I recommend JSON paths evaluators online.
Massage data to avoid conflicts when inserting to Hive
This step is definitely not optimized. The point here is to escape the special characters to avoid errors when inserting into hive. The only thing I am doing here is removing the ‘ from the snippet as you can see, but it would deserve a second path I think:
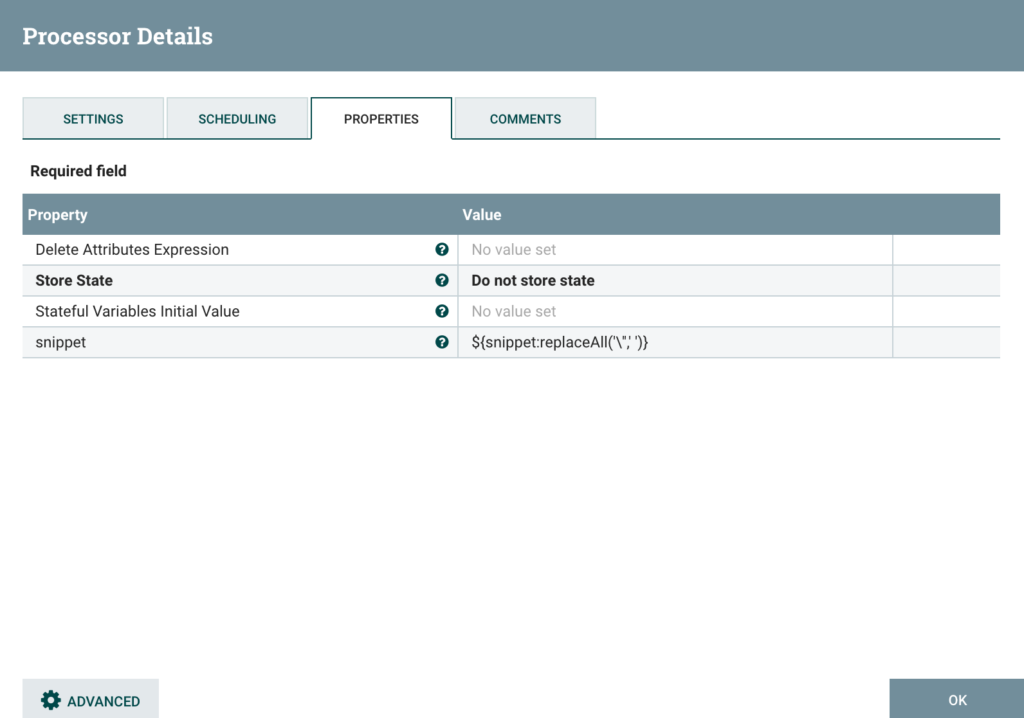
Step 2: Scrape HTML article data
Once we retrieved the meta data of the article, we must obtain the actual text of the article. For this, I’m using boilerpipe, an open source boilerplate removal and fulltext extraction from HTML pages (see reference for details).
Create a simple Java class to call boilerplate
After downloading the boilerpipe jars (using http://www.java2s.com/Code/Jar/b/Downloadboilerpipe120jar.htm), use your favorite Java IDE and create this simple class:
import de.l3s.boilerpipe.BoilerpipeProcessingException;
import de.l3s.boilerpipe.extractors.ArticleExtractor;
import java.net.MalformedURLException;
import java.net.URL;
public class extractArticle {
public static void main (String args[]) throws MalformedURLException, BoilerpipeProcessingException {
if(args.length == 1) {
URL url = new URL("" + args[0]);
String text = ArticleExtractor.INSTANCE.getText(url);
System.out.println(text);
} else {
System.out.println("Please Specify URL");
}
}
}
Once tested, create an executable jar (in my case extractArticle.jar).
Transfer jars to nifi server
Connect to your nifi server with your nifi user and create the following directory structure:
$ cd /home/nifi
$ mkdir extractArticle
$ cd extractArticle
$ mkdir lib
Transfer the following libraries to ~/extractArticle/lib/ :
- xerces-2.9.1.jar
- nekohtml-1.9.13.jar
- boilerpipe-sources-1.2.0.jar
- boilerpipe-javadoc-1.2.0.jar
- boilerpipe-demo-1.2.0.jar
- boilerpipe-1.2.0.jar
- extractArticle.jar
Create a simple Unix script to execute HTML scraping
Under ~/extractArticle/ create the script extract_article.sh as follows:
#!/bin/bash
JDK_PATH=/usr
LIB1=./lib/xerces-2.9.1.jar
LIB2=./lib/nekohtml-1.9.13.jar
LIB3=./lib/boilerpipe-sources-1.2.0.jar
LIB4=./lib/boilerpipe-javadoc-1.2.0.jar
LIB5=./lib/boilerpipe-demo-1.2.0.jar
LIB6=./lib/boilerpipe-1.2.0.jar
LIB7=./lib/extractArticle.jar
LIBS=$LIB1:$LIB2:$LIB3:$LIB4:$LIB5:$LIB6:$LIB7
$JDK_PATH/bin/java -Xmx512m -classpath $LIBS extractArticle $*
Configure ExecuteStreamCommand processor
Configure the processor to pass the URL in argument and outputting the output stream to the next processor, as follows:
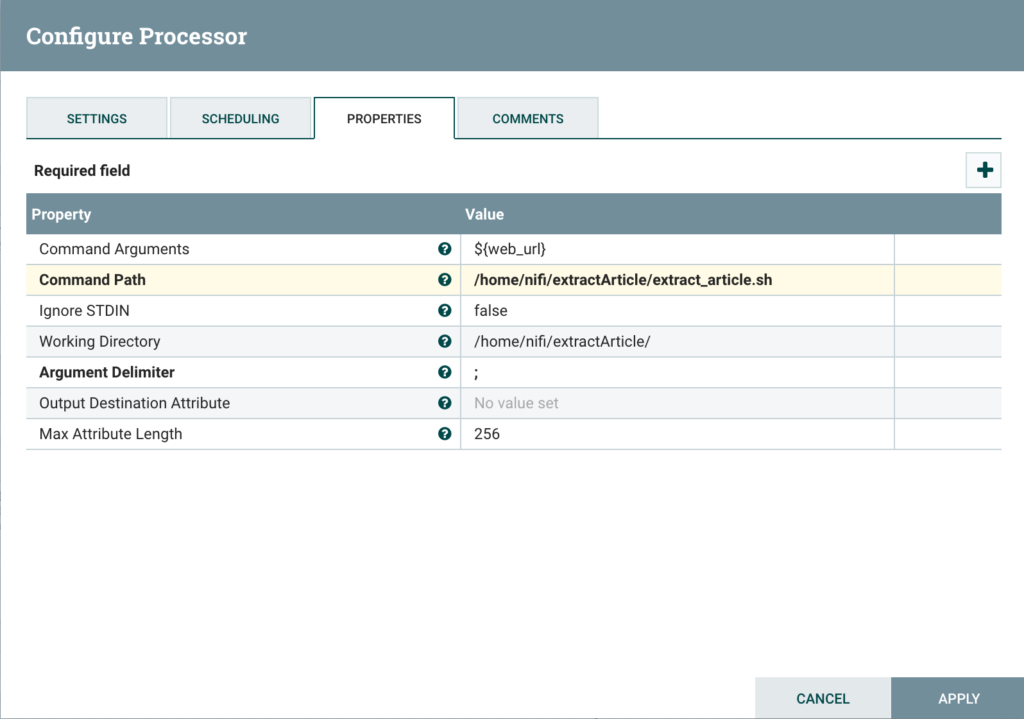
Step 3: Run machine learning models for personality detection
Setup PersonalityRecognizer on NiFi server
Just as for boilerpipe, we’re going to run an ExecuteStream command. To prepare the files, run the following commands:
$ cd /home/nifi
$ wget http://farm2.user.srcf.net/research/personality/recognizer-1.0.3.tar.gz recognizer-1.0.3.tar.gz
$ tar -xvf recognizer-1.0.3.tar.gz
$ cd PersonalityRecognizer
$ mkdir texts
Modify the file PersonalityRecognizer.properties as follows:
##################################################
# Configuration File of the Personality Recognizer
##################################################
# All variables should be modified according to your
# directory structure
# Warning: for Windows paths, backslashes need to be
# doubled, e.g. c:\\Program Files\\Recognizer
# Root directory of the application
appDir = /home/nifi/PersonalityRecognizer
# Path to the LIWC dictionary file (LIWC.CAT)
liwcCatFile = ./lib/LIWC.CAT
# Path to the MRC Psycholinguistic Database file (mrc2.dct)
mrcPath = ./ext/mrc2.dct
Modify the script PersonalityRecognizer as follows:
#! /bin/bash -
# ENVIRONMENT VARIABLES
JDK_PATH=/usr
WEKA=./ext/weka-3-4/weka.jar
# ----------------------------------
COMMONS_CLI=./lib/commons-cli-1.0.jar
MRC=./lib/jmrc.jar
LIBS=.:$WEKA:$COMMONS_CLI:$MRC:bin/
$JDK_PATH/bin/java -Xmx512m -classpath $LIBS recognizer.PersonalityRecognizer $*
Finally, create a wrapper script that, using the latest file from the folder texts runs PersonalityRecognizer and outputs only the results in a json format:
#!/bin/bash
text=`ls -t texts/ | head -1`
./PersonalityRecognizer -i ./texts/$text > tmp.txt
extraversion=`cat tmp.txt | grep extraversion | grep -Eo '[+-]?[0-9]+([.][0-9]+)?'`
emotional_stability=`cat tmp.txt | grep emotional | grep -Eo '[+-]?[0-9]+([.][0-9]+)?'`
agreeableness=`cat tmp.txt | grep agreeableness | grep -Eo '[+-]?[0-9]+([.][0-9]+)?'`
conscientiousness=`cat tmp.txt | grep conscientiousness | grep -Eo '[+-]?[0-9]+([.][0-9]+)?'`
openness_to_experience=`cat tmp.txt | grep openness | grep -Eo '[+-]?[0-9]+([.][0-9]+)?'`
json_output="{\"web_url\" : \"$1\", \"extraversion\" : \"$extraversion\",\"emotional_stability\" : \"$emotional_stability\",\"agreeableness\" : \"$agreeableness\",\"conscientiousness\" : \"$conscientiousness\",\"openness_to_experience\" : \"$openness_to_experience\"}"
echo $json_output
rm tmp.txt texts/*
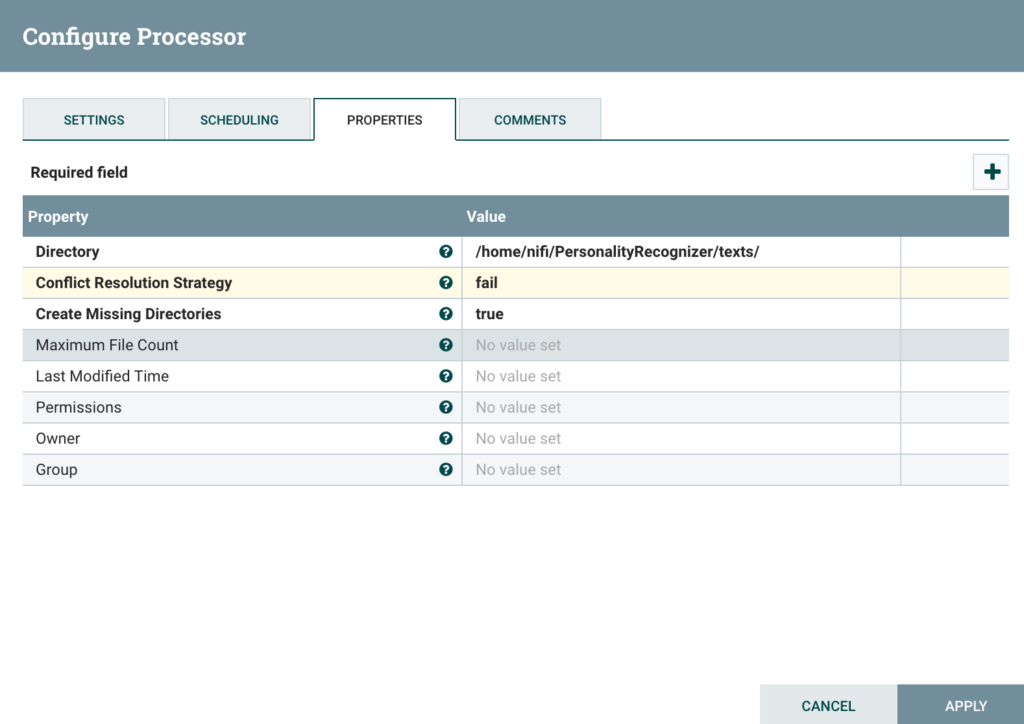
Configure PutFile processor to create article file
This processor takes the output stream of the HTML scraping to create a file, under the appropriate folder, as shown below:
Configure the ExecuteStreamCommand Processor
Just as for HTML scraping, configure the processor to pass the URL in argument and outputting the output stream to the next processor, as follows:
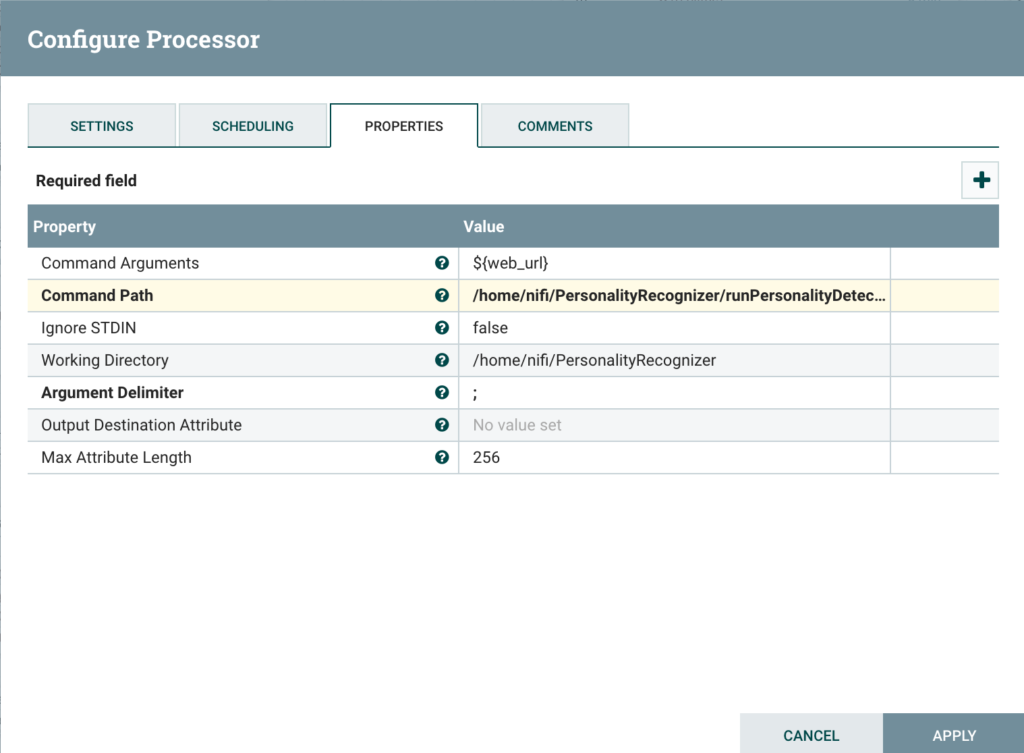
Extract attributes from JSON output
Using EvaluateJSONPath, retrieve the results of the PersonalityRecognizer to attributes:
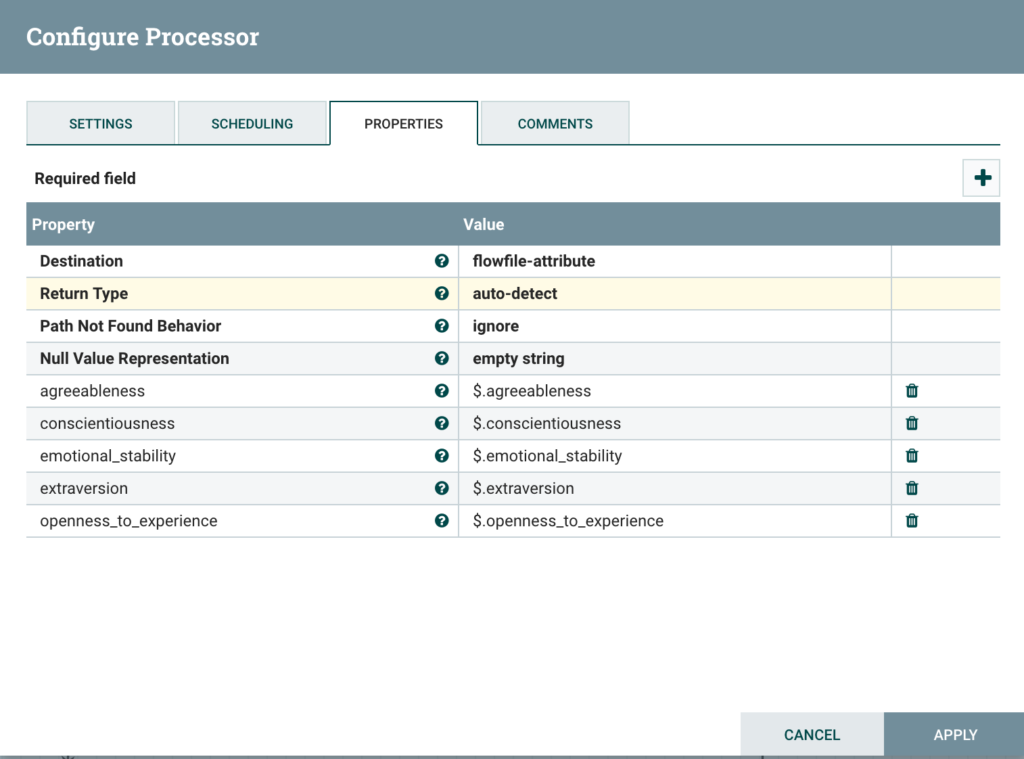
Step 4: Store results to Hive
Create Hive DB and tables
Because we don’t control wether we receive the same article twice from the New York Times API, we need to make sure that we don’t insert the same data twice into Hive (i.e. upsert data into Hive). Upsert can be implemented by two tables and the merge command.
Therefore connect to your hive server and create one database and two tables as follows:
CREATE DATABASE personality_detection;
use personality_detection;
CREATE TABLE text_evaluation (
web_url String,
snippet String,
byline String,
pub_date date,
headline String,
document_type String,
news_desk String,
last_updated String,
extraversion decimal(10,4),
emotional_stability decimal(10,4),
agreeableness decimal(10,4),
conscientiousness decimal(10,4),
openness_to_experience decimal(10,4)
)
clustered by (web_url) into 2 buckets stored as orc
tblproperties("transactional"="true");
CREATE TABLE all_updates (
web_url String,
snippet String,
byline String,
pub_date date,
headline String,
document_type String,
news_desk String,
last_updated String,
extraversion decimal(10,4),
emotional_stability decimal(10,4),
agreeableness decimal(10,4),
conscientiousness decimal(10,4),
openness_to_experience decimal(10,4)
) STORED AS ORC tblproperties ("orc.compress" = "SNAPPY");
Create HiveQL script
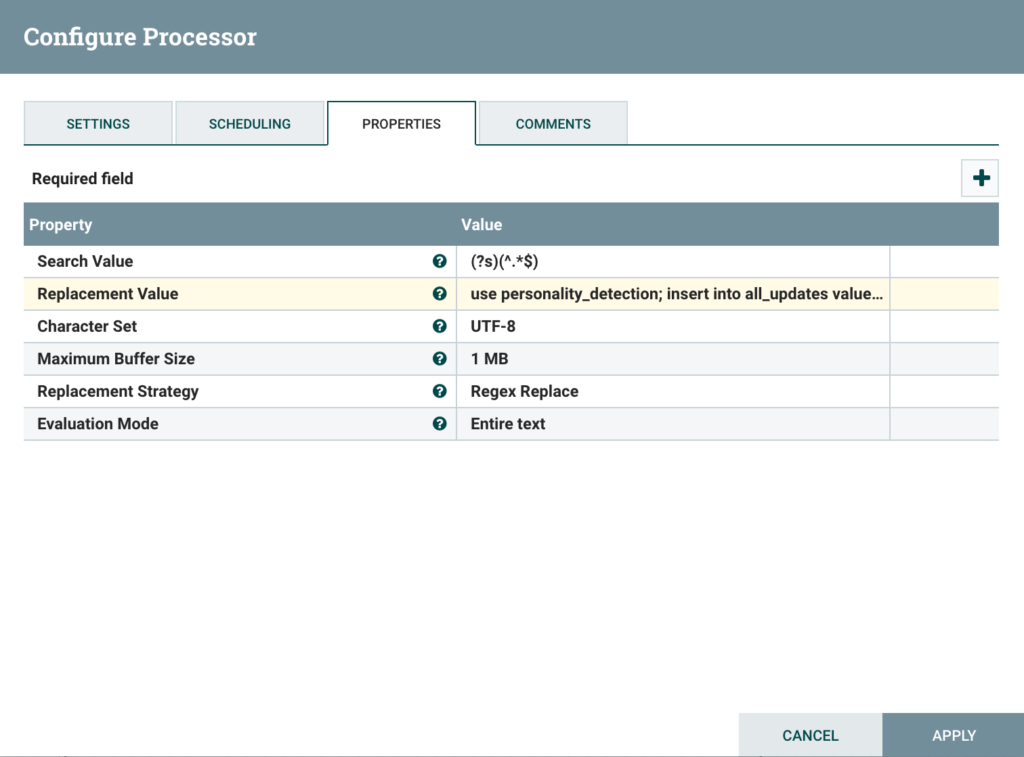
Using a ReplaceText processor, create the appropriate HiveQL command to be executed to upsert data into your tables from the data collected in the flow.
Code for Replacement Value (note that I remove the timestamp from the pub_date here, because I’m storing it as a date):
use personality_detection;
insert into all_updates values('${web_url}','${snippet}','${byline}','${pub_date:substring(0,10)}','${headline}','${document_type}','${news_desk}','${now()}','${extraversion}','${emotional_stability}','${agreeableness}','${conscientiousness}','${openness_to_experience}');
merge into text_evaluation
using (select distinct web_url, snippet, byline, pub_date, headline, document_type, news_desk, extraversion, emotional_stability, agreeableness, conscientiousness, openness_to_experience from all_updates) all_updates on text_evaluation.web_url = all_updates.web_url
when matched then update set
snippet=all_updates.snippet,
byline=all_updates.byline,
pub_date=all_updates.pub_date,
headline=all_updates.headline,
document_type=all_updates.document_type,
news_desk=all_updates.news_desk,
last_updated=from_unixtime(unix_timestamp()),
extraversion=all_updates.extraversion,
emotional_stability=all_updates.emotional_stability,
agreeableness=all_updates.agreeableness,
conscientiousness=all_updates.conscientiousness,
openness_to_experience=all_updates.openness_to_experience
when not matched then insert
values(all_updates.web_url,all_updates.snippet, all_updates.byline, all_updates.pub_date, all_updates.headline, all_updates.document_type,
all_updates.news_desk, from_unixtime(unix_timestamp()), all_updates.extraversion, all_updates.emotional_stability, all_updates.agreeableness, all_updates.conscientiousness, all_updates.openness_to_experience);
truncate table all_updates;
Processor Overview:
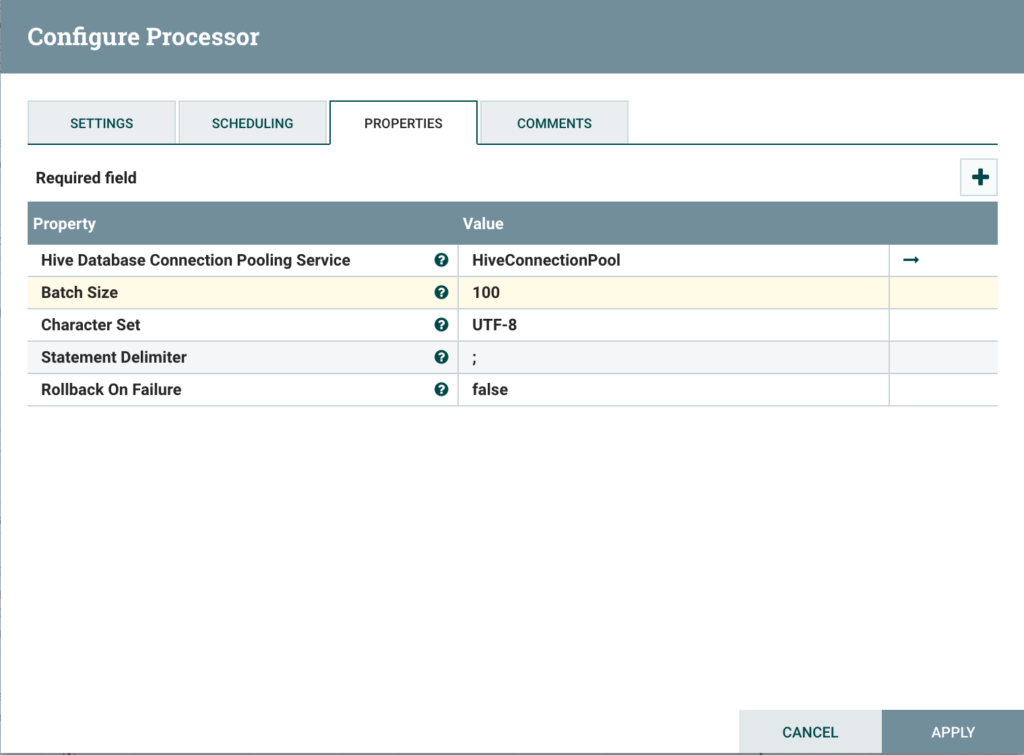
Upsert data to hive
Finally, configure a simple PutHiveQL processor as follows (make sure you configured your HiveConnectionPool beforehand):
Step 5: Create simple Zeppelin notebook
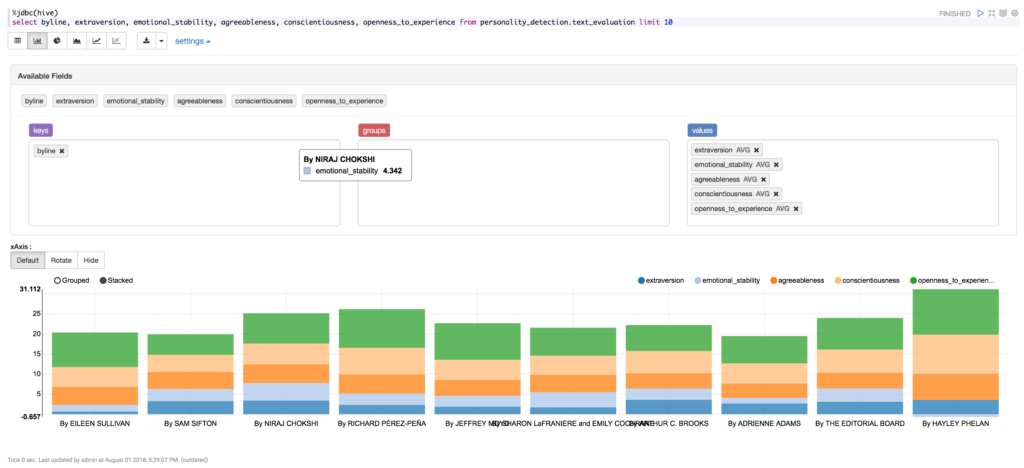
Lastly, after running the NiFi flow for a while, create a simple Zeppelin notebook to show your result. This notebook will use the jdbc interpreter for Hive and run the following query:
%jdbc(hive)
select byline, extraversion, emotional_stability, agreeableness, conscientiousness, openness_to_experience from personality_detection.text_evaluation limit 10
Then, you can play with Zeppelin visualizations to display the average of the big 5 by byline:
Conclusion
While being a very simple, this exercise is a good starting point for on-the-wire personality recognition. More importantly, in an age of information overload or even misinformation, having the ability to classifying the psychology of a text on the fly can be extremely useful. I do plan on tinkering with this project, improving performance, optimizing models and ingesting more data, so stay tuned!
Known possible improvements
- Better control of data retrieval to avoid duplicate flows (depends on API)
- Better special character replacement for HiveQL command
- More elegant way to execute data scraping and run personality recognition java classes
- Additional scraping from article text to remove title, byline, and other unnecessary information from boilerpipe output
- More thorough testing of different personality recognizer models (and use other/more recent libraries)
References
- Big Five personality traits: https://en.wikipedia.org/wiki/Big_Five_personality_traits
- The Big-Five Trait Taxonomy: History, Measurement, and Theoretical Perspectives: http://moityca.com.br/pdfs/bigfive_john.pdf
- IBM Watson Personality Insights: https://personality-insights-demo.ng.bluemix.net/
- Personality Recognizer by Francois Mairesse: http://farm2.user.srcf.net/research/personality/recognizer
- NYT API sign up: https://developer.nytimes.com/signup
- NYT API FAQ: https://developer.nytimes.com/faq
- NYT Article Search readme: https://developer.nytimes.com/article_search_v2.json#/README
- JSON Path Evaluator: http://jsonpath.com/
- Boilerpipe jar download: http://www.java2s.com/Code/Jar/b/Downloadboilerpipe120jar.htm
- Boilerpipe github: https://github.com/kohlschutter/boilerpipe



